
"Where’s Waldo?", But for your Data
Why 1touch.io matters when enterprises finally admit they do not really know what they have

This past Saturday, my wife and I sat at my son’s college graduation ceremony doing what every proud parent does after running out of tears and tissues: staring at the giant screen, scanning a crowd of thousands, and playing a very emotional, very expensive version of Where’s Waldo?
The camera pulled back and showed the graduating class. Thousands of caps. Thousands of gowns. Thousands of people who had just survived exams, group projects, late-night studying, bad cafeteria decisions, emotional phone calls home, and whatever personal version of “I’ll start the paper tomorrow” they subscribed to. Somewhere in that sea of mostly identical academic robes was my son.

I knew he was there. We had dropped him off at college years earlier, paid tuition, bought supplies, endured move-in day, survived the separation anxiety, worried about him, cheered for him, and occasionally pretended to be calmer than we actually were. I knew exactly why we were in that room.
But on that screen, in that moment, he was just one face among thousands.
So I started searching for him. Every parent around me was probably doing some version of the same thing. We were not looking at a graduating class in the abstract. We were looking for our graduate. Everyone else on that screen mattered deeply to someone, but to us they were mostly context without identity: a massive, moving, emotional dataset with almost no metadata attached.
That was the strange thing about the picture.
It showed us everything and told us almost nothing.
There were thousands of people on the screen, but unless you already knew who you were looking for, you did not really know what you were looking at. Somewhere between the pride, the camera angle, and my increasingly poor performance at parental facial recognition, my brain did what my brain unfortunately does. It connected a very human moment to the way enterprises think about data.
Because this is exactly the problem most organizations have with their data.
They know it is there. They know there is a lot of it. They know some of it is incredibly valuable, some of it is probably risky, and some of it is duplicated, outdated, forgotten, regulated, misplaced, or being accessed by people and systems nobody has thought about in years. But knowing there is a crowd is not the same thing as knowing who is in it.
That is the part we do not talk about enough.
For years, data management conversations were mostly about where the data lived, how it was protected, how fast it could be accessed, and how much it cost to keep it all running.
Those things still matter. They will always matter. But they are no longer enough.
The new question is not simply, “Where is the data?”
The better question is, “What is this data, who does it belong to, why does it exist, who is using it, where has it moved, what risk does it carry, and should this AI model, business process, analyst, application, or employee be touching it at all?”
That is a very different conversation, and that is why 1touch matters.
Not because the industry needed one more product logo, one more acronym, or one more keynote phrase that sounds important until everyone quietly admits they are not exactly sure what it means. 1touch matters because it is aimed directly at the problem of not knowing.
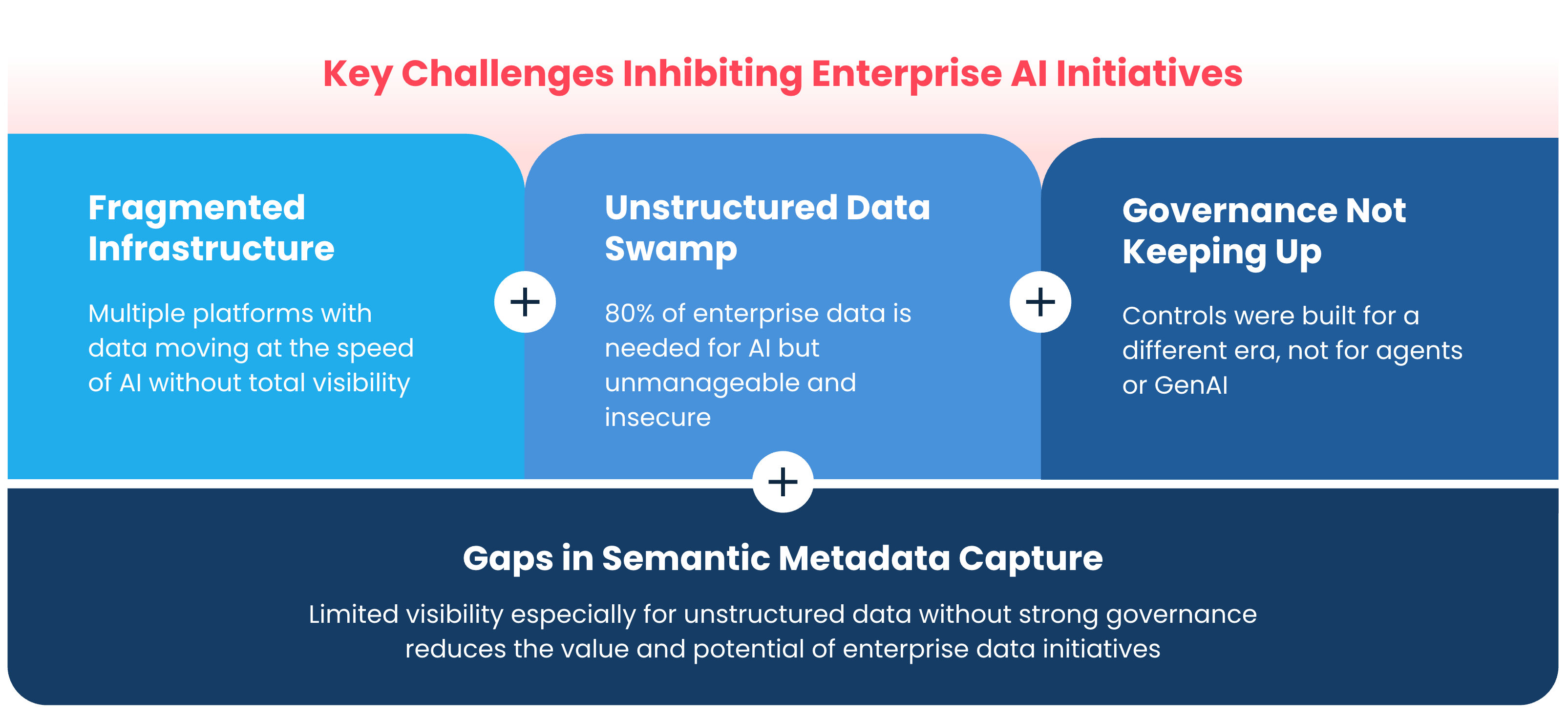
The lie of visibility
Most organizations believe they have visibility into their data because they have tools that can show them infrastructure. They can show arrays, volumes, file systems, buckets, databases, dashboards, latency charts, replication status, backup jobs, snapshots, anomalies, alerts, and the occasional red icon that ruins someone’s morning.
All of that is useful. None of it guarantees understanding.
An IT team can tell you a volume is 87 percent full, but that does not mean they know it contains expired customer records, old HR exports, forgotten underwriting files, production data copied into a test environment, or a spreadsheet with 40,000 Social Security numbers created in 2018 by someone who left the company three reorganizations ago.
A security team can tell you an alert fired, but that does not mean they know whether it represents real exposure, a false positive, or just another noisy event in a pile nobody has enough hours to investigate. A data team can point to a lake, a warehouse, a catalog, and a governance process, but that does not mean the data is clean, trusted, current, properly classified, or safe to feed into an AI workflow.
This is the uncomfortable truth: enterprise data visibility has often meant visibility into containers, not contents.
We could see the auditorium. We could count the very uncomfortable seats. But we still could not tell which graduate was my son.
The graduation screen was not useless. It showed scale. It proved the event was real. It helped me understand the crowd. But until I could identify the person I cared about, the picture was incomplete.
Enterprise data estates work the same way. The problem is not that organizations have no tools. They often have too many. The problem is that many tools see the surface of the environment but miss the identity, relationship, movement, and meaning of the data inside it.
That gap was inconvenient in the old world. In the AI world, it is dangerous.
AI does not forgive ignorance
Before generative AI entered every boardroom conversation, the consequences of not knowing your data were already serious: compliance exposure, bloated infrastructure costs, security blind spots, slow audits, manual discovery, painful legal requests, cloud migration delays, and business users waiting weeks for access to information because nobody could confidently say what was safe to use.
Then AI showed up and made the problem louder.
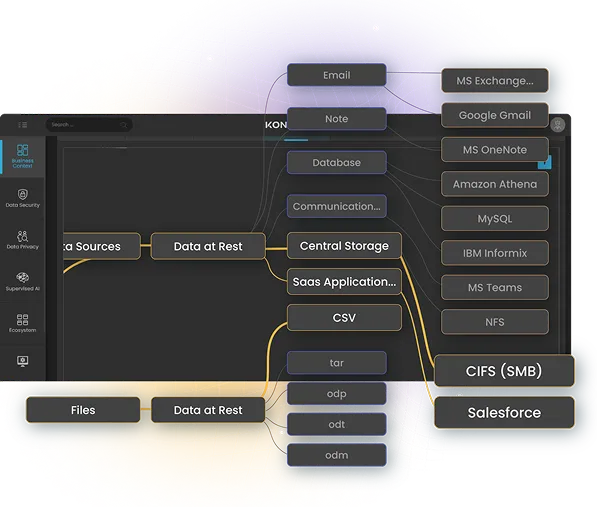
AI feeds on data. Lots of it. Structured data, unstructured data, documents, emails, transcripts, PDFs, customer records, logs, knowledge bases, support case histories, SaaS exports, file shares, objects, and anything else that might help a model answer a question, summarize a situation, automate a workflow, or make a decision.
That sounds exciting until you remember that most enterprises do not fully know what is in all of those places.
And AI is not magic. If the input is wrong, the output inherits that problem. Sometimes the model hallucinates. Sometimes it exposes something it should not. Sometimes it makes a recommendation based on data that was never supposed to leave a specific jurisdiction. Sometimes it answers confidently from a document that was obsolete three policies ago.
Sometimes it gives the right answer to the wrong person, which may be the scariest version of all because the technology can look like it is working while quietly violating the trust model of the business.
That is why “AI-ready data” cannot simply mean “we pointed a model at a repository.” That is not readiness. That is hope with an API call.
AI-ready data needs context. It needs classification, identity, policy, and confidence. It needs a way to distinguish between a harmless document, a restricted record, a regulated attribute, an exposed credential, and a data fragment that only becomes sensitive when connected to other fragments somewhere else.
A number or a name by itself may not mean much. A location, transaction, or timestamp by itself may not mean much either. But connect the number to the name, the name to the patient record, the patient record to a geography, the geography to a regulation, the regulation to a storage location, and the storage location to an access path, and suddenly you are not looking at random data anymore.
You are looking at risk. Or value. Often both.
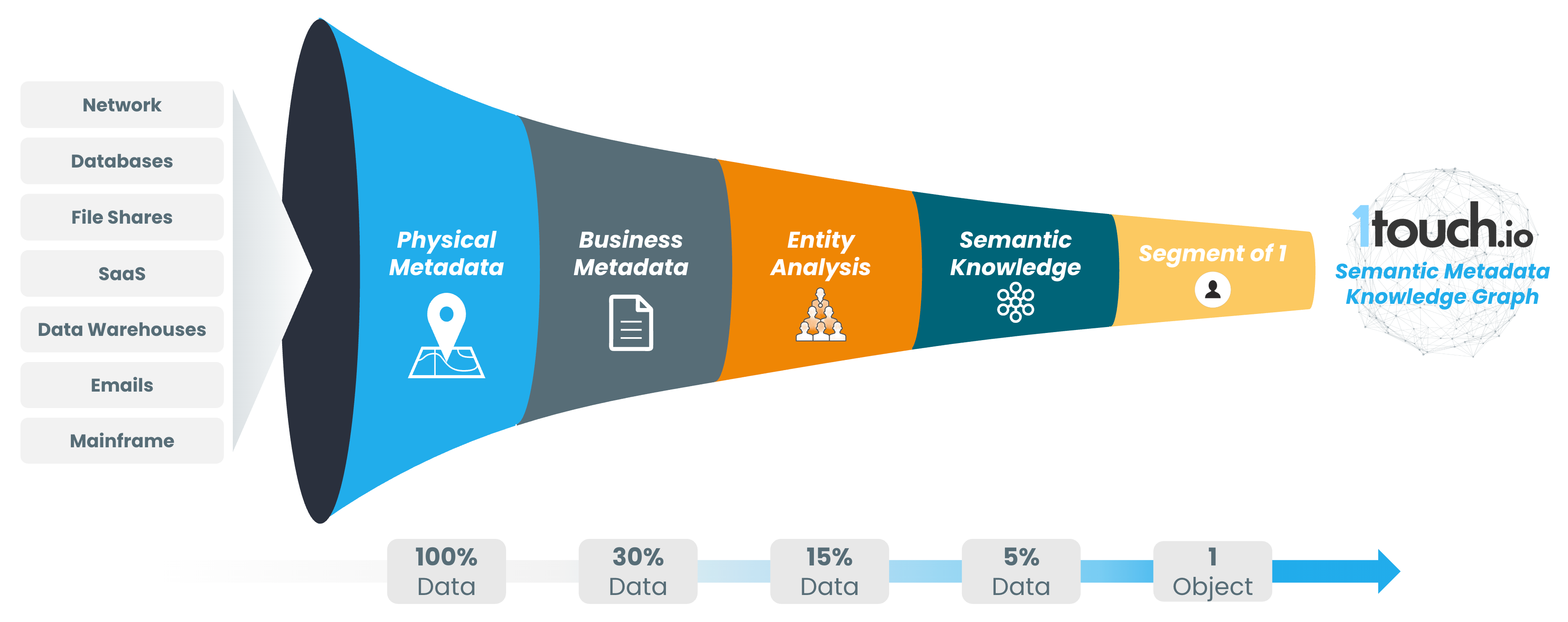
This is where 1touch becomes important, because its value is not just identifying patterns and sticking labels on files. Its value is in discovering, classifying, and contextualizing data across environments so organizations can understand not only what exists, but what it means.
That distinction matters.
The difference between labeling and knowing
At graduation, every student had the same basic label: graduate. That label was accurate, but it was wildly insufficient.
One graduate may be heading to medical school. Another may be joining a startup. Another may be the first person in their family to earn a degree. Another may have worked two jobs to get there. Another may have changed majors three times and somehow still finished on time, which frankly deserves its own medal.

The label tells you the category. The context tells you the story.
Data works the same way. A traditional tool might identify something that looks like a credit card number, Social Security number, email address, medical code, account number, or passport field. That is useful, but it can also create noise. Strings of digits appear everywhere. Test data looks real. Real data looks fake. A file name can lie. A folder path can be misleading. A database column called “ID” might be harmless, or it might be the key to everything.
Context is what turns a guess into intelligence.
1touch approaches this problem by looking at the broader semantic environment around the data. It is not just asking, “Does this pattern match something sensitive?” It is asking, “What surrounds it? What system did it come from? Who accesses it? Where does it move? What other data is connected to it? What business process does it support? What regulatory meaning does it carry?”
That matters because in the real world, data risk rarely lives in a single isolated field. It lives in relationships.
The same way my son was not immediately identifiable to the room because he was wearing a cap and gown like everyone else, sensitive enterprise data is often not obvious because it is dressed like everything else. It sits in file shares, databases, cloud repositories, SaaS platforms, mainframes, archives, exports, and forgotten project folders. It blends into the crowd.
The old approach was to scan the crowd every so often and hope you recognized enough faces. The newer requirement is continuous understanding: discovering data where it lives, watching how it moves, connecting fragments across systems, and building a living map of identity, access, classification, and risk.
Not a once-a-year inventory. Not a spreadsheet. Not a governance theater exercise where everyone nods in a meeting and then goes back to copying production data into development because the test system “needed something realistic.”
A living map.
That is the real promise.
Why this matters
The value of 1touch can be easy to undersell if we describe it only as sensitive data discovery or Data Security Posture Management (DSPM). Those descriptions may be accurate, but they are not the business problem.
A prospect is not waking up hoping to buy a classification engine. They are waking up with pressure from the board, auditors, regulators, cyber insurers, application owners, AI initiatives, cloud migration teams, and business leaders who want faster access to “clean” data without increasing risk.
And for those of us who have been around this industry long enough to have a few emotional support scars, this problem is not new. We were talking about lifecycle data management and data classification projects 20 years ago. Kazeon, StoredIQ, and others were all trying to help customers understand what was hiding inside their unstructured data environments before the phrase “dark data” became a fashionable way to describe a very unfashionable mess.
I personally used Kazeon back in 2006, before EMC acquired it and eventually killed it EMC Acquires Kazeon 2009. The idea was right. The experience was painful.
I remember a project where it took almost two months to scan the environment, process the results, and prepare the report. We finally sat down with the customer, proudly showed them the findings from roughly 5TB of unstructured data, and waited for the moment where they would appreciate all the classification goodness we had brought into their lives.
Instead, the customer looked at us and asked the only question that mattered:
“Where is the rest of my 55TB?”
There are moments in a technical meeting when the room temperature changes without the thermostat being involved. This was one of them.
Apparently the tool did not have permissions to scan the rest of the environment. So after two months of work, the result was technically accurate and practically incomplete, which is the most dangerous kind of confidence. We had a report. We had charts. We had findings. What we did not have was the whole truth.
That is why this matters now. The enterprise data problem did not begin with AI. AI simply made the consequences of incomplete understanding much harder to ignore. Twenty years ago, a bad classification project meant a frustrated customer, an awkward meeting, and a lot of manual cleanup. Today, the same kind of blind spot can contaminate an AI pipeline, expose regulated data, break a sovereignty policy, delay a migration, or give executives a false sense of security.
For existing customers, the value is even more strategic. They already trust the platform to store, protect, move, and serve their data.
The next logical question is whether it can help them understand the data as well.
That is the bridge 1touch helps build.
That is important because customers are tired of stitching together disconnected tools where one product sees storage, another sees identity, another sees security events, another sees data catalogs, another sees cloud posture, and another sees compliance workflows. Everyone sees something, but nobody sees enough.
Customers do not need more fragmented visibility. They need connected context.
Most importantly, it helps us explain why the conversation has moved from where data sits to what the data actually means.
Back to the screen
Eventually, during the ceremony, I found my son. Definitely when his name was announced and he walked across that stage. That was the moment all the pride (mixed with tears of joy), worry, and years of parenting caught up with me.
But the moment stayed with me because it was such a simple reminder: seeing a crowd is not the same as knowing the people in it.
Every person on that screen had a story, a history, a family somewhere in the stands trying to yell the loudest, and a future that was about to begin. From a distance, they looked identical. Up close, they were anything but.
Enterprise data is like that too. From a dashboard, it can look like capacity, files, objects, tables, volumes, buckets, repositories, shares, records, and logs. But inside that data are customer identities, patient histories, citizens tax records, contracts, intellectual property, employee information, business secrets, stale copies, duplicate exports, forgotten archives, useful insights, hidden risks, and the raw material for the next generation of AI-driven business processes.
The organizations that win will not be the ones that simply store the most data.
They will be the ones that know what their data means.
That is why 1touch matters.
Because the future of data management is not just finding Waldo.
It is understanding the entire crowd.
Appreciate you reading.
Dmitry Gorbatov
© 2025 Dmitry Gorbatov | #dmitrywashere