
The Machine Was Always Going to Need Power
What Person of Interest, backyard AI nodes, and the physics of enterprise infrastructure have in common

If you have been following along for a while, you already know about the “undocumented feature” in the #dmitrywashere operating system. The one where movie and TV show lines attach themselves to my brain and then find their way into conversations where most reasonable people would have said something normal instead.
I have mentioned Friends. I have mentioned The Big Bang Theory. I have referenced Joey Tribbiani nodding along to a conversation he had completely stopped following, which, if I am being honest, described my first several weeks of hearing people talk about MCP.
This time, the show that has been bothering me is Person of Interest (2011-2016).

If you never watched it, the premise was built around an artificial intelligence called The Machine, a system that had been given access to essentially every surveillance network imaginable and used that access to identify people who were either about to commit violence or about to become victims of it. The moral complications of that premise were part of what made the show interesting, but that is not the part I want to talk about.
The part that has been living rent-free in my head lately is what happens to The Machine when it is threatened.
At a certain point in the story, The Machine can no longer exist safely in one location. Being centralized has stopped being a strength and started being a liability. So it does something that felt like very clever television writing when I first watched it and has started to feel more like a reasonable infrastructure decision every time I think about it now. It distributes itself.
Not into a cloud platform. Not into a purpose-built facility with access control and a cooling system and a vendor-sponsored naming opportunity on the front of the building. It moves into the electrical grid itself, into utility boxes, into the kind of anonymous infrastructure that lines every street and hangs from every pole while everyone walks past it without ever stopping to think about what it actually does.

The first time I saw that, I thought the writers were being clever.
I still think they were being clever. I just think they were also accidentally writing about 2026.
Because here we are, and there is an actual company called SPAN that has announced something called XFRA, which is a distributed data center concept that places compute nodes at residential and small commercial locations. NVIDIA is listed as a launch partner. PulteGroup, which is a national homebuilder, is involved in the pilot. The nodes use liquid-cooled NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs. Fortune reported that SPAN has already deployed prototype units in Northern California, describing them as cabinet-sized nodes installed on the sides of homes and small businesses, with the stated goal of tapping into underutilized residential electrical capacity to build AI compute capacity faster and at lower cost than conventional centralized data centers can be built.

I want to say something carefully here, because this story has been traveling around the internet in a version that is somewhat cleaner and more exciting than the verified facts support. The rumor version says NVIDIA wants to put mini data centers in your backyard and pay you for hosting them. That version has the advantage of being the kind of sentence people like, forward and repost immediately, which is probably why it is the version most people have seen.
The real version is that SPAN is proposing this concept, with NVIDIA as a partner, and that the homeowner value proposition appears to involve subsidized electricity and internet rather than a straightforward monthly cash payment. That distinction matters if you are making a decision based on it. It matters less if what you are really trying to understand is what it means that this conversation is happening at all.
And that is what I keep coming back to. Not whether backyard AI nodes become a standard part of residential landscaping in American suburbs. Not whether your HOA is going to approve the GPU box before or after the fence dispute. But the reason this idea is being taken seriously by real companies with real capital and real partners.
It is being taken seriously because AI has made power the constraint that everything else is now organized around.
That shift happened faster than most of the enterprise IT world has fully adjusted to, and I think it is worth being honest about why.
For most of my career, power was present in every data center conversation, but it was rarely the conversation. It was part of the facility design. It was part of the colocation contract. It was something the colo provider or the building manager or the facilities team worried about, and something that showed up on someone else’s line item in a way that was easy to treat as overhead rather than strategy.
Storage teams talked about capacity and latency and replication and snapshots and protection policies and cyber resilience.
Compute teams talked about virtualization, CPU density, memory ratios, GPU allocation, and increasingly Kubernetes. Network teams talked about bandwidth, latency, fabric design, and east-west traffic.
Application teams talked about response time, throughput, scalability, and the user experience.
Business teams talked about outcomes, timelines, and cost.
Power was in the room. But it was rarely the point.
What changed is that AI workloads have a completely different energy profile than the workloads enterprise IT was built around. The traditional enterprise environment had a rhythm to it that the infrastructure had been designed over many years to accommodate. Workloads were bursty in ways that were relatively predictable. Applications had peak periods and quiet periods. Databases absorbed load and relaxed. Batch jobs ran during specific time windows. Users followed patterns. The data center breathed in a way that the cooling systems, power distribution designs, and rack densities were engineered to handle.
AI workloads do not breathe the same way. Training runs can sustain intense load for days or weeks without interruption. Inference, which tends to sound lighter when described per individual transaction, becomes a constant background hum when it is embedded into enough applications, workflows, copilots, search experiences, security tools, development environments, and business processes simultaneously. The load does not feel like the old load. The heat does not feel like the old heat. The planning assumptions that went into the physical infrastructure do not hold in the same way.
The International Energy Agency has projected that global data center electricity consumption could more than double by 2030, reaching approximately 945 terawatt-hours, and it points specifically to AI as a primary driver of that growth. That number is large enough to be almost emotionally useless in conversation. Most people cannot feel a terawatt-hour. It is like telling someone the ocean is very deep. True, and accurate, and somehow insufficient to produce a useful response.
So I find it more helpful to think about it in terms of what it means for a specific customer in a specific building trying to do a specific thing.
I think about the organization that has spent several years consolidating, virtualizing, deduplicating, tiering, and modernizing, and has done a genuinely good job of it, and is now sitting in a building whose power design reflects the assumptions of the era when all of that work was done. I think about the team that wants to add GPU capacity for AI workloads and is discovering that the ceiling on that ambition is not the GPU budget, is not the vendor selection, is not the use case validation, and is not the executive alignment.
The ceiling is watts. I think about the CIO who has been told by the business that AI is a priority and has agreed that it is, and who is now discovering that priorities do not override physics. I think about the customer who says they want to do AI and is somewhere in the process of realizing that wanting to do AI is a different sentence than being able to support AI with the physical infrastructure they actually have.
None of that is a failure of imagination or ambition. It is a collision between a very reasonable set of technology goals and a very honest set of physical constraints. The constraints were always there. AI made them visible in a way that earlier workloads generally did not.
This is where I think the data storage conversation starts to matter more than it usually gets credit for.
It is easy to make the AI infrastructure story mostly about GPUs, and in terms of raw power consumption, that framing is not wrong. A modern AI accelerator draws more power than almost anything else in the rack, and high-density GPU configurations push data center power planning into territory that many traditional facilities were never designed to handle. But the GPU is not sufficient as the full explanation, partly because the GPU is almost never the bottleneck people think it is, and partly because a GPU that cannot get data fast enough is not doing the work it was purchased to do.
A GPU waiting for storage is still consuming power.
It is still producing heat. It is still occupying space and contributing to the facility’s total load. It is just not converting any of that into useful computational output.
In the economics of AI infrastructure, idle GPU time is one of the most expensive things that can happen, because the cost of the GPU does not pause while the data pipeline catches up.
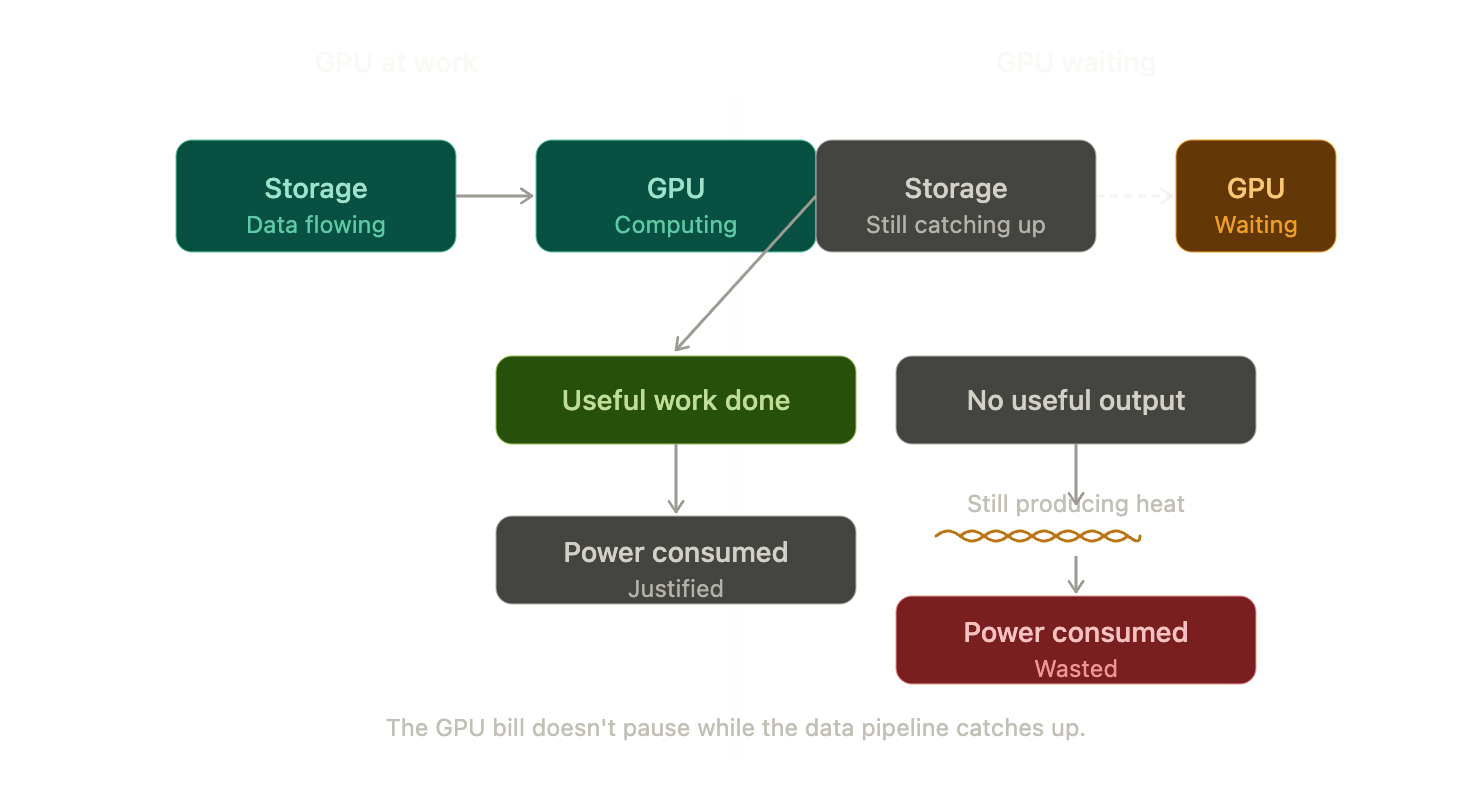
This means that storage architecture is not separate from the power conversation. It is part of it. The physical footprint of the storage platform contributes to rack density and cooling load. The data reduction efficiency of the platform determines how much raw capacity is required to hold a given amount of useful information, and therefore how much hardware is required, and therefore how much power that hardware consumes. The number and complexity of components in the architecture — controllers, drives, network equipment, management infrastructure — all carry power overhead. The refresh cycle of the platform determines how often new hardware is purchased, deployed, and powered up to replace hardware that is being retired, and that cycle has an energy cost too.
None of this means that all storage architectures are equal from an energy perspective, and the industry has started to reflect that awareness. Vendors are talking about watts per terabyte, IOPS per watt, rack density per effective capacity, long lifecycle upgrades, intelligent data reduction, disaggregated architectures, and designs that reduce the amount of hardware required to deliver a given outcome. Some of those claims will survive scrutiny better than others.
In enterprise technology, the tradition of every vendor winning their own benchmark is deeply honored, and I would read competitive comparisons with appropriate skepticism regardless of who is making them.
But the direction of the conversation is real, and it reflects a genuine shift in what efficiency means. For years, when data storage professionals talked about efficiency, the primary frame was capacity. How much usable storage could be extracted from a given amount of raw media, after deduplication and compression and thin provisioning? How many effective petabytes fit in a rack? How much could a customer defer buying by getting more from what they already had? Those questions are still valid, but they are no longer the whole story. The more complete question now includes how much useful work an architecture delivers per watt consumed, per rack occupied, per refresh cycle, and per operational hour. That is a different optimization target, and it implies different design decisions.
What I find interesting about the SPAN XFRA story, beyond the obvious novelty of it, is that it makes this constraint visible in a way that a data center planning spreadsheet does not. SPAN’s argument is essentially that grid interconnection for a large centralized data center can take four to seven years in some markets, and that building capacity faster requires finding power that already exists and is not being fully used. SPAN positions XFRA for inference workloads specifically, which makes architectural sense — distributed residential nodes cannot coordinate the way tightly coupled GPU clusters need to for large-scale training runs.
That distinction is worth sitting with, because it suggests something about where AI infrastructure is actually heading. The centralized hyperscaler datacenter is not going away. It is where the large training runs happen, where the enormous models are built, where the compute density is highest and the coordination requirements are most demanding. But inference, which the research suggests will account for the substantial majority of AI energy consumption by 2030, may be more distributed than the centralized model implies. And if inference can run at the edge of the grid, then the grid itself starts to look less like a constraint and more like an architecture.
That is where The Machine, as a metaphor, keeps coming back to me.
The Machine survived by understanding that centralization was not a permanent advantage. When centralization became a vulnerability, it distributed itself into the infrastructure that was already everywhere. It did not wait for someone to build it a better facility. It used what existed.
Whether or not the SPAN approach succeeds in the way the launch materials describe — and there are real questions about serviceability, security, hardware refresh logistics, regulatory considerations, and whether the economics hold outside of a controlled pilot — the underlying observation is sound. The demand for power to run AI infrastructure is growing faster than the traditional systems for building and connecting centralized power capacity can accommodate. That gap is real. Closing it requires looking at the infrastructure that already exists, including infrastructure that most enterprise IT conversations have historically treated as someone else’s problem.
For those of us who work in technology sales and pre-sales engineering, I think this means something specific about how we should be talking to customers. We have spent years getting comfortable with conversations that focus on performance, capacity, availability, recoverability, and cost. Those are still the right conversations. But underneath each of them, there is now a power dimension that is no longer optional to understand. When a customer asks whether a storage platform can support their AI workload, they are not only asking whether it is fast enough. They are asking whether it can feed their GPUs without wasting the power those GPUs need to do useful work. They are asking whether the physical footprint of the platform fits within the physical limits of their environment. They are asking whether the architecture will force them to consume more rack space, more cooling capacity, and more operational overhead than a better-designed alternative would require.
A customer with available power has architectural options. A customer who has run out of available power has to have a different conversation, and that conversation tends to be slower, harder, and more expensive than the original architecture conversation would have been.
That is probably the least glamorous lesson that AI has taught enterprise IT in the last few years.
Everything we thought we had abstracted away is still there.
The rack is still there. The cooling is still there. The power feed is still there. The transformer is still there. The grid interconnection timeline is still there. The heat is still there. The bill is still there. And the physical limits of the building where all of this has to actually work are still there, indifferent to how many times the strategy deck has been updated.
The irony of the last decade of enterprise IT is that we got very good at making infrastructure feel invisible. Cloud made it feel infinite. Virtualization made it feel flexible. SaaS made it feel like someone else’s concern. Storage efficiency made capacity feel almost elastic. Consumption models made hardware feel like a subscription. Even the language shifted toward things that do not have weight or heat or power requirements: fabrics, services, platforms, ecosystems, experiences, journeys.
AI walked back in and reminded everyone that underneath every layer of abstraction is still a physical system, and physical systems operate within physical constraints, and physical constraints do not negotiate with executive timelines.

The Machine eventually found power in the grid because it had no other choice.
Enterprise IT is finding something similar, not in utility boxes on street poles, but in the cumulative reality that there is no software release that makes a missing megawatt appear, no contract clause that relocates heat from a dense rack, and no roadmap presentation that makes a four-year grid interconnection queue shorter.
The architecture has to be right. The platform has to be efficient. The infrastructure has to respect the physics of the environment it lives in.
And the conversation about AI has to include the conversation about power, not as a footnote that facilities handles and everyone else ignores, but as a genuine design constraint that shapes every decision from the storage platform selection to the refresh cycle to the cooling strategy to the building capacity plan.
Because the machine still needs power.
And this time, unlike on television, there is no clever plot device that makes the constraint disappear.
There is only good architecture, or the absence of it.
Appreciate you reading.
Dmitry Gorbatov
© 2025 Dmitry Gorbatov | #dmitrywashere
I love this observation about "every vendor winning their own benchmark". So true!
Thanks for explaining this in layman terms. I vaguely understood the whole data center discussion already, but this makes it much more concrete.