
The Data Center Pendulum
From Converged → Hyper-Converged → “Wait… why are we separating things again?”

I’ve been around long enough to stop believing that data center infrastructure trends are linear.
They’re not. They’re a pendulum.
Every few years, the industry looks at the last architecture and says: “This is too complicated, too rigid, or too expensive.”
Then it swings hard in the opposite direction — confident, loud, and usually convinced this time is final.
It never is.

First Swing: “We’re done being our own integrator”
Converged Infrastructure wasn’t born out of innovation.
It was born out of exhaustion.
vBlock, FlexPod, FlashStack — all different implementations of the same quiet admission:
“We don’t want to assemble infrastructure during an outage anymore.”
Validated designs mattered.
Predictable failure domains mattered.
Knowing who owned the problem at 2:00 AM mattered.
Converged infrastructure wasn’t glamorous — but it was honest.
And for a while, that honesty won.

Converged infrastructure didn’t promise magic. It promised fewer surprises.
Second Swing: “We’re done managing storage”
Then HCI arrived with confidence.
No SANs.
No LUNs.
No storage teams negotiating treaties with virtualization teams.
Just nodes. Clusters.
One-click upgrades and policy-driven everything.
And to be fair — HCI delivered.
For small to mid-scale environments, with predictable growth and balanced workloads, it simplified operations in a very real way.
But then something subtle started happening.

The Moment the Math Stops Working
There’s a specific sentence that marks the beginning of the end of HCI elegance:
“I don’t need more compute — I just need capacity.”
That’s when the cracks show.
Storage doesn’t grow like CPU.
Databases don’t care about your node symmetry.
AI workloads laugh at your “balanced cluster” assumptions.
And licensing makes every extra node feel… personal.
HCI doesn’t fail at scale.
It just becomes inefficient in very expensive ways.
If your storage refresh turns into a CPU and licensing negotiation, the architecture is trying to tell you something.
Enter dHCI: The Industry’s Nervous Tick
Instead of admitting that tightly coupled HCI has limits, the industry did what it always does:
It invented a new acronym.
dHCI
(distributed / disaggregated / decentralized — pick your favorite flavor)
The pitch is familiar:
keep the HCI operating model
keep centralized lifecycle tooling
keep the “platform” story
But quietly… separate compute and storage again
Which is unintentionally hilarious.
Because it means the industry spent a decade saying decoupling was the problem — and then brought it back as the solution.
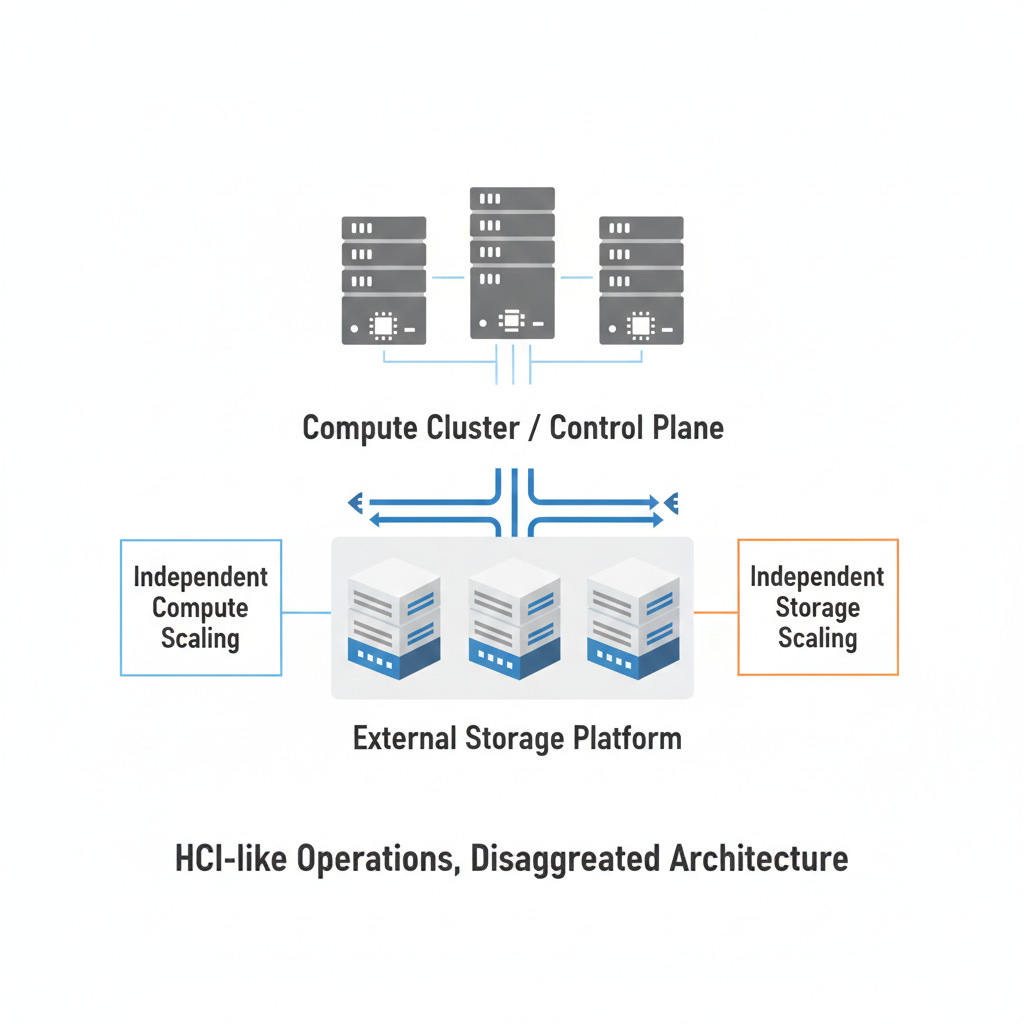
dHCI isn’t a breakthrough. It’s an admission.
The Irony Nobody Likes to Say Out Loud
Here’s the part we don’t usually say on stage.
Many vendors who once declared “SAN is dead” are now shipping architectures that look an awful lot like:
shared storage
over fast Ethernet
with modern protocols
wrapped in automation
validated end-to-end
Just… without calling it a SAN.
The pendulum didn’t swing back because CI was wrong.
It swung back because CI needed better ergonomics, not abandonment.
Why FlashStack with Nutanix Feels Like the Pendulum Settling
This is why the latest FlashStack with Nutanix release matters — quietly, not loudly.
CVD for Pure Storage FlashStack with NUTANIX
It doesn’t pretend the past was stupid.
It acknowledges reality:
compute and storage grow differently
independent scaling is a feature
simplicity comes from tooling, not artificial constraints
Architecturally, it’s refreshingly direct:
Nutanix runs the compute and control plane
Pure runs the storage platform
Cisco provides validated fabric and lifecycle glue
NVMe/TCP makes separation fast and boring (the good kind)
No rebranding gymnastics.
No “trust us” hand-waving.

Just a clean, validated way to run modern infrastructure.
I wrote about the benefits of Nutanix / Pure Storage Integration in this post: Why the Nutanix + Pure Storage Partnership Matters - Part 4
Good architecture doesn’t fight reality. It works with it.
Sidebar: What I’d Tell a SLED CIO Who’s Been Burned Twice
(This is the quiet conversation — not the slideware version.)
You’ve already lived through:
one platform that promised simplicity and delivered lock-in
another that promised flexibility and delivered integration pain
So here’s the honest advice:
Don’t chase architectures that require perfect growth patterns
Don’t buy platforms that only work if your org never changes
Don’t confuse “simpler to sell” with “simpler to operate”
In SLED, you need:
predictable costs
independent refresh cycles
architectures that survive budget pauses, staffing gaps, and procurement timelines
and support models that don’t collapse during fiscal year transitions
If an architecture only works when everything goes right —
it won’t survive public sector reality.
The Actual Lesson
Every infrastructure wave solves the pain of the one before it — and introduces new tradeoffs.
CI reduced risk.
HCI reduced friction.
dHCI exists because scale exposed rigidity.
The best architectures today don’t claim perfection.
They accept that:
growth is uneven
teams are smaller
outages are less tolerated
and nobody wants to relearn their platform every refresh cycle
FlashStack with Nutanix doesn’t try to win a purity contest (pun intended).
It just respects how data centers — and people — actually work.
And honestly? That’s the most modern move the industry’s made in a while.
Dmitry Gorbatov
© 2025 Dmitry Gorbatov | #dmitrywashere